- Free E-Book
- A Comparative Study Of The Effects Of Subliminal Messages On Academic Performance
- A Comparative Study Of The Effect Of Subliminal Messages On Public Speaking Ability
- Study – Binomial Trial Study
- Study – Subliminal Messages for Pain
- Study – Subliminal Audio Information: Subliminal Audio’s
- Study – Technical Bullitin
- Study – The difference in cigarettes consumed by the three groups
- Study – Weight Loss Study by Michael Urban, Ph.D.
- Study – Technical Update
Technical Update
by
MIDWEST RESEARCH OF MICHIGAN
In our previous “Technical Bulletin” we addressed several of the more prominent “controversies” in the field of subliminal audio tape production. Based on the response to the “Bulletin” we found that the distributors and users of Midwest of Michigan subliminal products were far more interested in technical issues than we had ever suspected. In response to calls and letters we have received, this “Update” will elaborate on the “blank tape” controversy.
For those of you unfamiliar with this so-called “controversy”, it was initiated through rather poorly done investigations whose results were uncritically and sensationally reported as the “subliminal hoax”. While the reporting of such misinformation is obviously irresponsible, little has been done to correct this misperception of subliminals. We will now attempt to set the record straight.
The Truth about Subliminal Sound
In our previous report we presented the following graph:
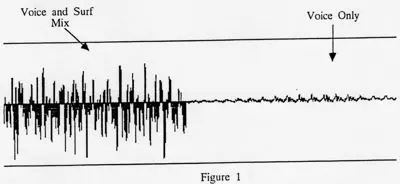
in which the left-hand part of the picture represented the digitized appearance of broad-band masking, or surf sounds, and the right-hand side showed the wave forms of the affirmation; “Learning is easy and effortless”. The picture was meant to demonstrate that the affirmations are invisible, both to the naked eye and electronically, as long as they are masked by a sound such as surf. Of importance in the picture above is the fact that the affirmations are present in their original form when the masking sound is removed. Hence it is possible to retrieve voice from the original mix provided you know what it is that needs to be removed.
However, in actual practice the problem of retrieving a voice that has been mixed with a masking sound is a formidable task, and one that requires some rather expensive and sophisticated equipment. We were able to generate the data above because we knew in advance what the various components of both the masking sound and the voice were.
Someone who was not privy to this information, who was working from scratch, would find it difficult indeed to reconstitute the original voice as we have done.
Spectrograms
We are all familiar with the phenomenon of a prism, and its abilities to split light into a rainbow of colors. This rainbow represents the components of white or visible light. Sound is quite similar to color in that respect. It is really composed of a “rainbow” of frequencies, which when mixed together form the sounds that we recognize as speech, surf or music. And, again like light, it is possible to separate these sounds through the use of a “prism” although the sound “prism” is a mathematical one.
Through the application of mathematical “transforms” such as the popular Fast Fourier Transform (FFT) or in our case, the Fast Hartley Transform (FHT), it is possible to break sound down into its component frequencies. Shown below in Figures 2 and 3, are the spectral transforms of the same waveforms shown in Figure 1 of the previous page;
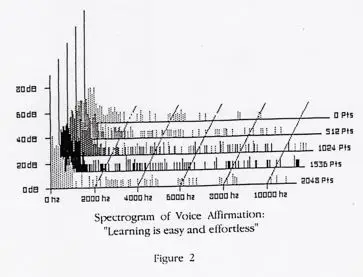
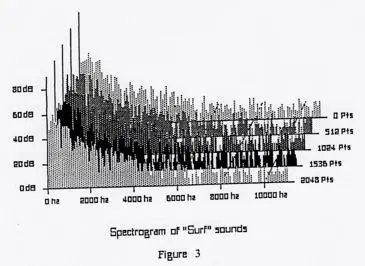
One can see by simple comparison, that the analysis of a digitized waveform in Figure 1, yields much less information than the analysis of the spectral components as displayed in Figures 2 and 3 above. In the case of the voice spectrum (Fig. 2), it now becomes clear that the fundamental frequencies are concentrated in a bandwidth of about 2000 Hz. with an amplitude of about 60 dB. In contrast, we can see that the surf spectrum (Fig. 3) reveals a broad range of frequencies, extending well above 10,000 Hz at an amplitude of 70-75 dB. What does this tell us? Well, for one thing, it now should be apparent that a sound composed of the spectrum of our “voice” can quite easily be “hidden” within the spectrum of the “surf” sounds.
Why then, a person might ask, has such controversy arisen over this issue? There are several answers to this, first; to the best of our knowledge, only Midwest Research of Michigan has taken the time and gone to the expense of gathering the kind of information we are presenting here. Spectral analysis has, until very recently, been an extremely difficult and time-consuming enterprise, and one that required a rather strong mathematical background. None of our critics have ever taken the time to run rigorous spectral analysis of our products. If they had, there would be no controversy at all.
However, even with the ability to do a spectral analysis, it is still quite difficult to retrieve an unchanged voice message from within a masking sound. Figure 4, seen below, shows the spectrum of the voice message mixed with the sound of ocean surf. Compare it to Figure 3, the spectrum of surf alone. Can you see a difference?
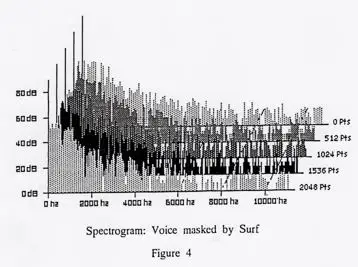
Obviously, it is quite difficult to distinguish between the graph of pure surf sounds and the graph of mixed surf and voice sounds even when we have done a spectral analysis.
Since it is virtually impossible to visually identify the presence of a subliminal message even in a spectrogram, it should be apparent and unequivocal that one cannot by any stretch of the imagination, prove or disprove the presence of a subliminal message by using the “oscilloscope” type of graph that we showed you on page one. Yet this is precisely what our detractors and sceptics have attempted to do. They simply have failed to do their homework and seemingly do not understand the technical aspects of a good subliminal audio product.
What Makes MIDWEST Subliminals Different
There is a right way and a wrong way to make subliminals. The wrong way is to combine a track of voiced affirmations with a track of masking sound on a studio quality mixing board to produce an audio subliminal. This is in fact what many other companies do. The result is illustrated below in Figure 5;
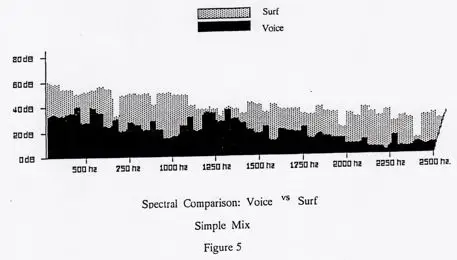
As can easily be seen from this illustration, when a tape is produced by this method, the voice is unevenly masked, sometimes by as much as 30 dB, and other times actually “bleeding through” the masking sound. This uneven masking will contribute to a perceptual distortion and markedly diminish the effectiveness of the tape.
Midwest Research of Michigan has engineered a proprietary subliminal mixer that gives us a product that is unparalleled in the industry. Our method maintains a constant difference between the voiced affirmations and the masking sound, and looks somewhat like the illustration in Figure 6, below;

Notice the constant difference, which is usually less than 10 dB, between the voice and the surf masking. The Midwest method optimizes the ability of the brain to retrieve the affirmations, and may be one reason that our customers have such excellent results with our products.
In the past we have chosen to let our satisfied customers do our talking for us. This time we’re speaking up for our customers to let them know that they have chosen well by purchasing a Midwest product. We are totally committed to providing consumers the best subliminal product on the market, period!
Hopefully this brief journey into the arcane science behind subliminal audio tapes has helped you understand a bit more about our product and why we think ours is the best that money can buy. Hopefully too, you will no longer be misled by those hoping to discredit subliminal technology or Midwest Research. Be assured that we deliver exactly what we claim, and that unlike our critics, we do understand our product!